
Can you remember the flood of mails you encountered on the first day after your last vacation? Sometimes it takes days to work through the mountains of mails.
Now imagine, that there would be someone, who categorizes all mails into a set of predefined categories for you.
This makes the bunch of mails less overwhelming, gives you an overview of topics included and eneases the first priorisation.
Here is where NLP (Natural Language Processing) comes into play. With NLP it is possible to train a machine learning model, which categorizes your mails according to a predefined set of categories.
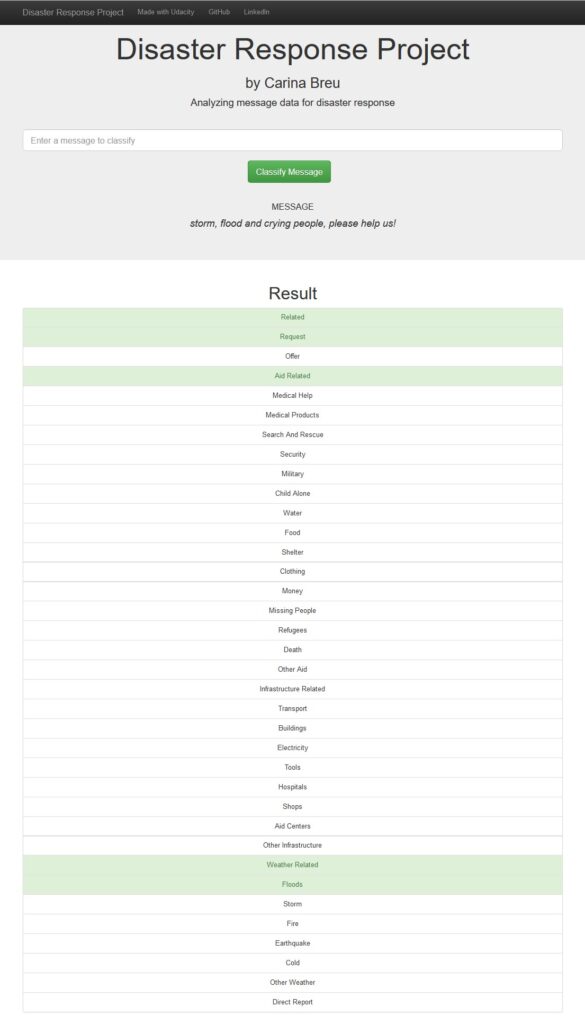
As part of my Udacity nanodegree course „Data Science“, I set up and trained a NLP-Pipeline to categorize messages during catastrophic events provided by Appen (www.appen.com). In a special web app, users can enter potential messages and let them be classified by the model.
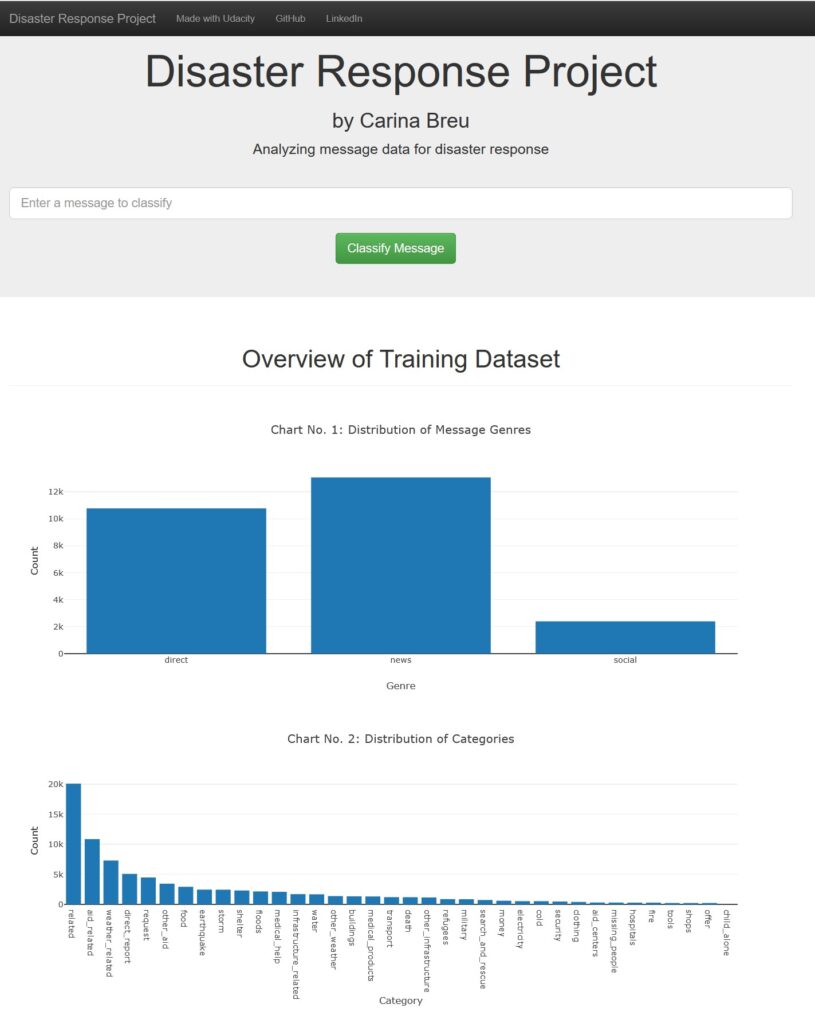
To get an idea about the training dataset, that the model is based on, the landing page additionally contains four summarizing statistics.
The first chart shows the genre of messages in the dataset, which is either „direct“, „news“ or „social“. In the second chart, the number of messages in each category is displayed.
Often messages are classified into several categories. The third chart shows the distribution of the number of categories per message. It is very interesting to see, that there are only very few messages with two categories, while messages with one or respectively 3-9 categories are more frequent.
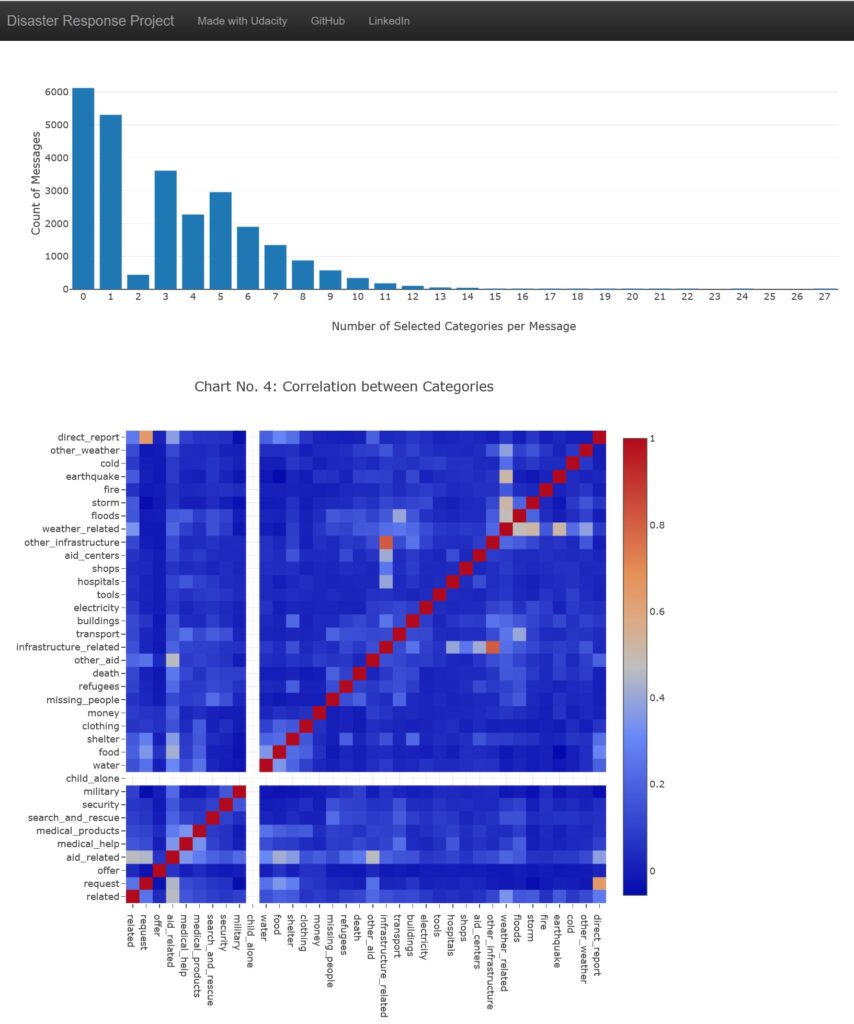
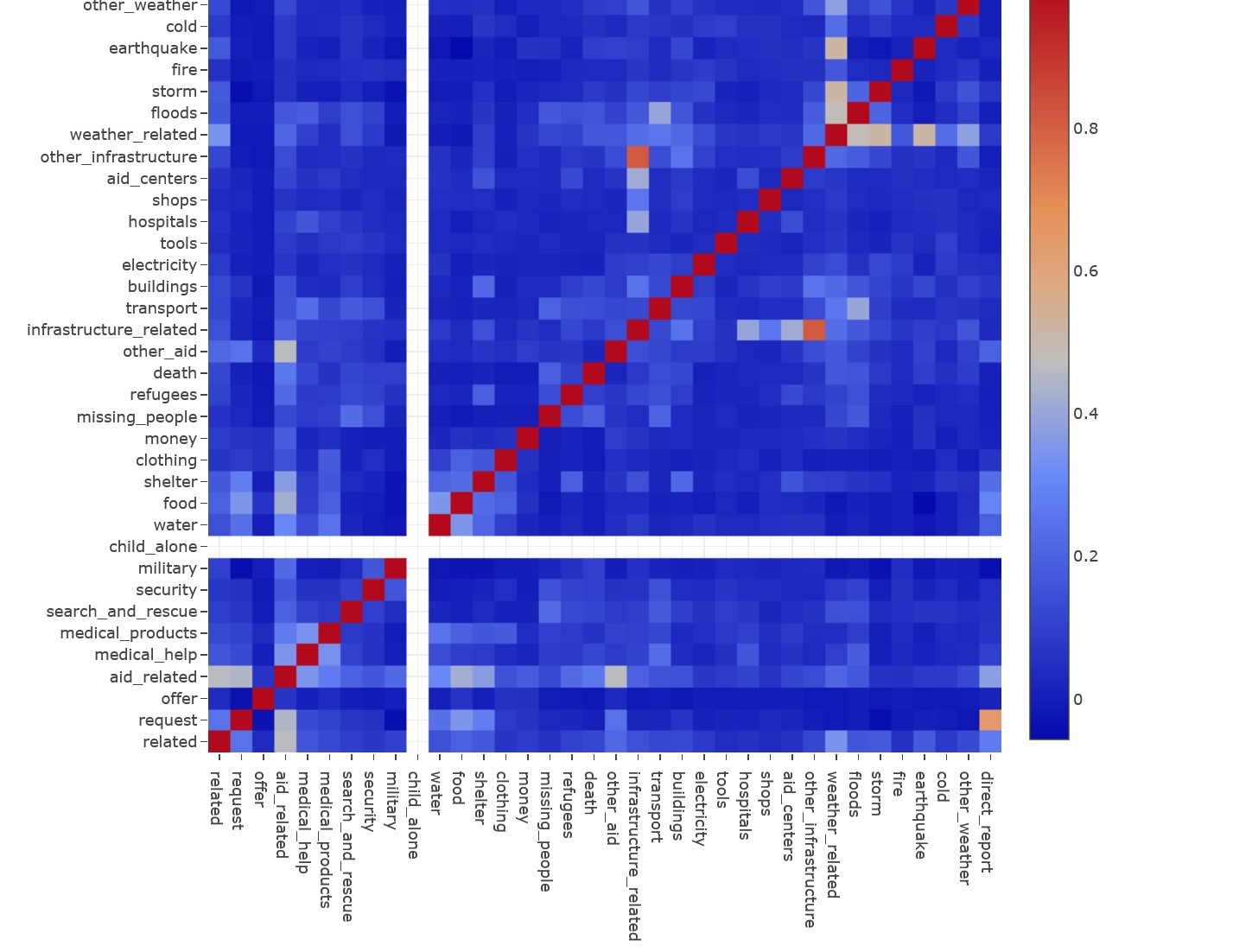
The last chart shows the correlation between categories. For example, it is likely that a message of the category „other_infrastructure“ is also part of category „infrastructure_related“.
Categories of catastrophic messages, however, would hardly fit in other surroundings and need to be adapted according to their purpose.
How would you categorize your mountain of mails?
If you are interested in more details of my Disaster Response Project, checkout my Github project here.