
Do you also know the moment, when an online recommendation almost exactly matches with products, that you have talked about in the last minute? Scary at first glance… But if online recommendations really match the interests of users, they may simplify the searching process and enhance the user experience of websites and platforms a lot.
As part of my Udacity nanodegree course in Data Science, I worked along a Jupiter Notebook to program three different recommendation systems on data about user interactions with articles, provided by IBM Watson.
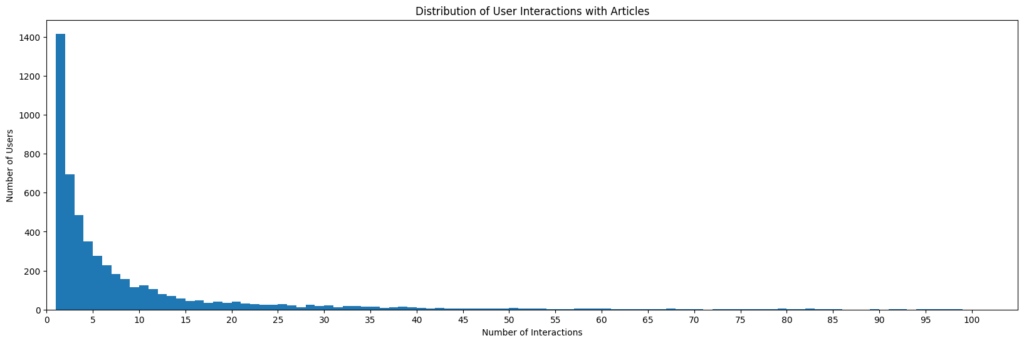
Some first exploratory data analysis shows, that most users interact with only very few articles. The median user shows up only 3 interactions!
The first recommendation system is rank-based. It recommends articles with the highest number of user-article interactions, but shows only articles which have not been seen by the user, yet.
The second recommendation engine is a user-user based collaborative filtering system. The system calculates the similarity to other users and recommends articles, that similar users have interacted with but the user has not seen, yet.
When there are several users of same similarity, the system prefers users, that have more interactions with articles. When chosing articles from this most similar user, the system prefers articles with most interactions over articles with fewer interactions.
The last recommendation system is based on matrix factorization. With Singular Value Decomposition (SVD) this system extracts latent features from user-article interactions and returns a model to calculate which articles also match latent features, the user preferred. For example, the system may recognize that a user interacts a lot with articles on Artificial Intelligence (AI) and will recommend further articles on that subject. Artificial Intelligence then would be the latent factor. However, we will not know from SVD, what exactly the latent features are. They will remain hidden, since they are just results of matrix decomposition.
The latter two systems do not work, when a user is new to the platform and does not have any article interactions so far. Therefore it is helpful to combine these systems with the rank-based system to provide recommendations for all users.
When implementing one or several of the above systems, I would recommend to accompany the launch by cookie-based-A/B-Testing. A possible measure would be the number of clicks on the recommended articles. Thereby we can validate, whether the recommendation engine is really matching the needs of the platform users.
If you are interested in more details of my recommendation engine project, checkout my Github project here.